|
Das Erbgut von Mensch und Schimpanse
Wie groß ist die genetische Verwandtschaft wirklich?
von Peer Terborg
Studium Integrale Journal
26. Jahrgang / Heft 1 - April 2019
Seite 4 - 10
|
 |
Zusammenfassung: Eines der populärsten Argumente für eine Abstammung des Menschen von affenartigen Vorfahren sind die Ähnlichkeiten im Erbgut von Mensch und Schimpanse. Die Zahl von ca. 99% Gemeinsamkeiten wurde oft zitiert. Neuere, genauere Analysemethoden offenbaren jedoch deutlich andere Zahlen.
|
|
|
Einleitung und Rückblick
Im Jahr 2005 wurde der erste Entwurf des Genoms des Schimpansen abgeschlossen und die Ergebnisse in der renommierten britischen Wissenschaftszeitschrift Nature veröffentlicht. Sehr bald nach dem Entschlüsseln des Genoms des Schimpansen wurde dessen Sequenz mit der des Menschen verglichen. Nach dieser Veröffentlichung, die den Vergleich beider Genome präsentierte, schien es nicht mehr als 2 % Sequenzdifferenz zwischen den beiden Arten zu geben:
„Da wir mehr als 98 % unserer DNA und fast alle unsere Gene teilen, sind Schimpansen der beste Ausgangspunkt, um nicht die Gemeinsamkeiten, sondern die winzigen Unterschiede zu untersuchen, die uns ausmachen“ (Gunter & Dhand 2005).
Dieses Ergebnis kam nicht unerwartet. Denn schon lange davor gab es bereits einen wissenschaftlichen Konsens, den wir auch in den Medien wiederfinden, dass nämlich über 98 % unserer DNA-Sequenzen auch im Schimpansen angetroffen werden. Die nun möglich gewordene vergleichende Genom-Analyse war die Bestätigung. Aber ist dies wirklich so?
Vor etwa 50 Jahren entwickelten Dave E. Kohne und Roy J. Britten eine Methode, um DNA-Unterschiede zwischen Arten zu messen (Britten 2002). Die Methode benutzte die Eigenschaft des DNA-Moleküls, Doppelstränge zu bilden. Je besser zwei DNA-Sequenzen sich paarweise zusammenlagern können, desto schwerer lassen sie sich bei Temperaturerhöhung wieder trennen. Die Trennung zweier DNA-Stränge bezeichnet man als das Schmelzen der Doppelhelix und man kann die Temperatur, bei der dies geschieht, sehr genau feststellen. Je besser die beiden DNA-Stränge zueinander passen, desto höher der Schmelzpunkt. Denn je mehr Basen (sozusagen die Buchstaben) der zwei verschiedenen DNA-Stränge sich paaren, desto stärker wird die Bindung zwischen den Strängen und desto mehr Energie kostet es, sie zu trennen. Seit den Siebzigerjahren des vorigen Jahrhunderts wird der Schmelzpunkt der DNA-Stränge gemessen, um das Ausmaß der Homologie (Ähnlichkeit) zwischen den DNA-Sequenzen, die von zwei verschiedenen Organismen stammen, festzustellen. Mit dieser Methode wurde der Unterschied zwischen den DNA-Sequenzen von Mensch und Schimpanse auf 1,76 % bestimmt. Diese Zahl bestätigte mehr oder weniger den Unterschied, den man zwischen Hämoglobin und Myoglobin gefunden hatte, die sowohl im Menschen als auch im Schimpansen vorkommen (King & Wilson 1975). Im Laufe der weiteren Forschung wurden jedoch Ergebnisse veröffentlicht, wonach unsere DNA immer mehr jener des Schimpansen zu gleichen schien. Eines der hervorragenden Institute im Bereich der vergleichenden DNA-Forschung ist das Max-Planck-Institut für evolutionäre Anthropologie in Leipzig. Im Jahre 2002 bestimmte eine dort tätige Arbeitsgruppe den genetischen Unterschied zwischen Mensch und Schimpanse mit nur 1,2 %. Dieser winzige Unterschied wurde abermals in einer Ausgabe von Nature im Jahr 2003 betont (Pääbo 2003). Im selben Jahr meldete eine Gruppe von Evolutionsbiologen, dass der genetische Unterschied zwischen Mensch und Schimpanse sogar nur 0,6 % betrage (Wildman et al. 2003). Die Evolutionsbiologen Scott Page und Morris Goodman gingen noch weiter und veröffentlichten eine Abhandlung, in der sie vorschlugen, Mensch und Schimpanse als zwei Mitglieder derselben Art aufzufassen (Page & Goodman 2001). Danach aber wurde die Next-Generation-Sequenzierung entwickelt und leitete damit eine Wende ein.
|
|
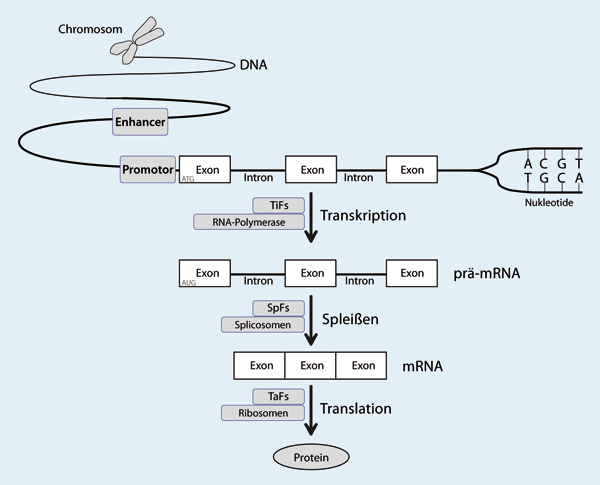
| Abb. 1: Die biologische Information, die in der Reihenfolge der Nukleotide (ATCG) der DNA vorliegt, befindet sich auf den Chromosomen, die die Gene enthalten. In höheren Organismen werden Gene aus Exons und Introns gebildet. Exons enthalten den Funktionscode, während Introns bei der Transkription (Umschreibung) herausgeschnitten werden. Durch Kombination verschiedener Exons können unterschiedliche Proteine gebildet werden. Die Transformation der Information in der DNA zur Herstellung von Proteinen erfolgt in mehreren Schritten. Zunächst bereiten Transkriptionsfaktoren (TiFs), die an Promotor- und/oder Enhancer-Sequenzen binden, die Abstimmung auf die RNA-Polymerase vor, das Enzym, das das Gen in ein Prä-Messenger-RNA (prä-mRNA)-Molekül transkribiert. Anschließend werden die Introns durch Enzyme, die als Spleißfaktoren (SpFs) bezeichnet werden, herausgeschnitten, was zur Bildung der reifen Boten-RNA (mRNA) führt, die nur die Exons enthält. Im letzten Schritt wird die mRNA in ein Protein übersetzt, das von den Ribosomen, einem Proteinkomplex, durchgeführt wird. |
Im Jahre 2002 verglich Roy J. Britten erneut eine große Menge DNA-Sequenzen des Menschen mit den Sequenzen des Schimpansen. Dieses Mal benutzte er die modernsten biologischen Techniken der direkten DNA-Sequenzierung, die mittlerweile völlig automatisiert worden waren. Die neuen Ergebnisse waren eindeutig. Britten (2002) schrieb Folgendes in der amerikanischen Zeitschrift Proceedings of the National Academy of Science:
„Die Folgerung, dass wir 98,5 % unserer DNA-Sequenzen mit dem Schimpansen gemein haben, ist wahrscheinlich nicht richtig. […] Eine bessere Einschätzung dürfte sein, dass 95 % der Nukleotiden der DNA des Menschen und Schimpansen ähnlich sind. Der Unterschied durch Basen-Substituten ist 1,4 % und es gibt noch einen zusätzlichen Unterschied von 3,4 % wegen des Vorkommens von Indels.“
Die Methode, die Kohne und Britten in den Siebzigerjahren des vergangenen Jahrhunderts anwandten, war nicht empfindlich genug, um Indels* (Insertionen und Deletionen, also Einschübe und Verluste) ausfindig zu machen.
Indels sind einzigartige DNA-Abschnitte, die man entweder nur im Menschen oder nur im Schimpansen antrifft (vgl. Abb. 2). Durch das Vorhandensein von Indels in den Protein-codierenden* DNA-Sequenzen werden sehr unterschiedliche Proteine synthetisiert. Die kleinen DNA-Abschnitte können nämlich große Folgen haben, wenn sie in Aminosäureabfolgen übersetzt werden und auf diese Weise die räumliche Struktur der Proteine bestimmen. Indels können in-frame-* oder out-of-frame*-Mutationen hervorrufen. Wenn sie out of frame sind, wird das Genproduct (Protein) meistens zerstört. Sind sie in frame, wird nur die Struktur des codierten Proteins gestört. Wenn die Indels lang genug sind oder (zufällig) an den „falschen“ Stellen sitzen, können die Proteine sogar ganz anders funktionieren.
|
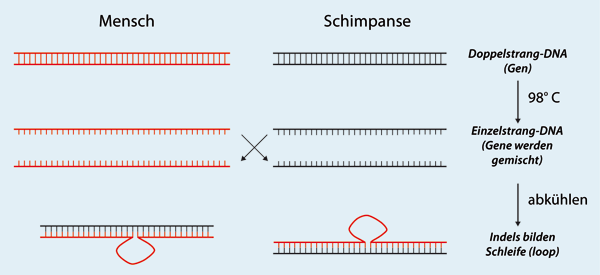
| Abb. 2: Wenn zwei homologe Gensequenzen verschiedener Arten wie Mensch und Schimpanse geschmolzen und dann miteinander gemischt werden, bildet nur der komplementäre Teil der Sequenzen einen doppelten hybriden DNA-Strang. In der Abbildung ist die menschliche Sequenz durch das Indel* länger, das im Schimpansen nicht zu finden ist. Das Indel kann keinen Doppelstrang bilden und bildet eine Schleife (loop), eine DNA-Struktur, die mit den in den 1970er-Jahren verwendeten Techniken nicht erkannt werden konnte. |
Mit der alten Methode konnten die Forscher die Indels nicht wahrnehmen, denn sie bilden gleichsam eine Schlinge (oder Schleife), die keinen Einfluss auf die Schmelztemperatur des doppelten DNA-Stranges hat. Die hochmodernen Techniken, mit denen man gegenwärtig DNA-Sequenzen Buchstabe um Buchstabe analysiert, detektieren solche zusätzlichen DNA-Abschnitte jedoch problemlos. Die Indels werden heutzutage als Folge von Mutationen aufgefasst, die erst nach der evolutiven Trennung der beiden Spezies Mensch und Schimpanse eintraten. Im Jahr 2011 wurden 584 humanspezifische konservierte Indels (kurz: hCONDEL) genauer untersucht. Diese Sequenzen mit einer mittleren Größe von 2.804 bp* werden in allen Primaten vorgefunden, fehlen aber vollständig im menschlichen Genom.1 Sie befinden sich fast ausschließlich in nicht-codierenden Regionen, und zwar häufig in der Nähe von Genen, die an der Signalweiterleitung von Steroidhormonen und an der neuronalen Funktion beteiligt sind, wo sie als regulatorische Elemente für die Genexpression* dienen können. Sie werden als gewebespezifische Verstärker (engl: enhancer*) diskutiert, die den regulatorischen Veränderungen zugrunde liegen können, die für die evolutionäre Divergenz von Mensch und Schimpanse notwendig sind (McLean et al. 2011). Interessanterweise wurde etwa die Hälfte dieser hCONDELs bei archaischen Menschen (Neandertaler und Denisovaner*) nachgewiesen, was zeigt, dass sie aus dem Genom des heutigen Menschen verloren gegangen sind (Cserhati et al. 2018).
Wenn man genetische Unterschiede zwischen den Arten feststellen möchte, sollten die Indels unbedingt berücksichtigt werden. Mit der Entdeckung der Indels ist der genetische Unterschied zwischen Menschen und Schimpansen auf fast 5 % angestiegen. Brittens Korrektur wurde später von der populärwissenschaftlichen Zeitschrift The New Scientist übernommen (Coghlan 2002). Trotzdem blieb dieses Ergebnis nahezu unbeachtet. Drei Jahre nach der Veröffentlichung von Brittens Ergebnissen meldete jedoch auch Science, dass der Unterschied 5 % betrage, wenn man die Indels mit einbezieht (Culotta 2005). Dennoch wurde weiterhin behauptet, dass Mensch und Schimpanse/Bonobo nur 1,3 % unterschiedlich seien (Prüfer et al. 2012), ein Prozentsatz, der dazu dient, die Abstammungsgeschichte zu popularisieren (Wong 2014). Eine detaillierte Literaturrecherche zeigt jedoch, dass seit Brittens Korrektur Hunderte vergleichende DNA-Analysen veröffentlicht worden sind, die bis heute alle von 1–2 % Unterschied berichten. Was könnten die Gründe für die Diskrepanz zwischen diesen Daten und jenen Brittens sein?
 |
| Wenn man genetische Unterschiede zwischen den Arten feststellen möchte, müssen die Indels unbedingt berücksichtigt werden. |
 |
|
Der Prozentsatz von 1–2 % zirkuliert bereits mehr als 20 Jahre in der biologischen Fachliteratur, in Zeitungen und in öffentlichen und sozialen Medien bis zum heutigen Tag. Dennoch kann er nur weiter propagiert werden, indem man die Rohdaten der biologischen Analysen im Voraus einer Datenauslese unterwirft. Die Algorithmen, die angewandt werden, um die evolutionären Analysen durchzuführen, sind derart programmiert, dass sie Indels als genetische Unterschiede automatisch verwerfen. Dennoch belegte Britten in 2002, dass Indels sogar den größten Teil der genetischen Unterschiede zwischen den Arten bilden. Vergleichende genetische Analysen sollen den Unterschied zwischen den Sequenzen von zwei oder mehr Organismen feststellen. Darum dürfen Indels hier keinesfalls fehlen. Diese Analysen zeigen allerdings, dass die hauptsächlichen Unterschiede nicht im homologen Teil der Genome vorhanden sind. Wir müssen auf die Suche gehen nach dem Teil der Sequenzen des menschlichen Genoms, der nicht im Schimpansengenom vorhanden ist. Und genau diesen Teil können wir ausfindig machen mit einer direkten Sequenzabgleichung der beiden Genome.
|
Um sich ein Bild von der Verwandtschaft verschiedener Organismen zu machen, können in unserer heutigen genetischen Ära Genome* direkt verglichen werden. Bezüglich des Erbguts von Mensch und Schimpanse herrscht jedoch nach wie vor erhebliche Unklarheit, insbesondere darüber, ob die beiden Genome nahezu identisch sind oder nicht. Diese Situation rührt daher, dass die Genome tatsächlich verschieden sind und man zuerst festlegen muss, was miteinander sinnvoll verglichen werden könnte. In den letzten zwei Jahrzehnten wurden viele vergleichende Genomstudien durchgeführt, die sich alle mit verschiedenen Aspekten des Genoms von Mensch und Schimpanse beschäftigten. Dies hat zu mehreren unterschiedlichen Prozentangaben bezüglich der Unterschiede geführt, die von weniger als 1 % Unterschied zwischen Mensch und Schimpanse bis hin zu 6,4 % reichen. Um diese Unterschiede zu erklären, wird eine Literaturübersicht gegeben und auf die verschiedenen Prozentangaben eingegangen. Die Daten zeigen, dass die 1 %-Differenz unhaltbar ist, während die neuesten Studien zeigen, dass die zwei Genome zu etwa 16 % unterschiedlich sind.
|
|
|
Der wirkliche Unterschied
|
| Von den 2,8 Milliarden DNA-Buchstaben der menschlichen DNA stimmten nur 2,4 Milliarden mit denen des Schimpansen überein. |
|
|
Die Entschlüsselung der ganzen Sequenz des menschlichen Genoms wurde 2004 fertiggestellt (International Human Genome Sequencing Consortium). Etwa zur gleichen Zeit standen auch die ersten Daten des Schimpansen-Genoms zur Verfügung. Einer der größten Vorteile der modernen genetischen Analysen ist, dass man die DNA-Sequenzen direkt, Buchstabe um Buchstabe, miteinander vergleichen kann. So kann man die Schimpansen-Chromosomen neben diejenigen des Menschen legen und dadurch genau feststellen, wo sich Unterschiede ergeben. Dadurch kann man einzigartige Gene und Sequenzen aufspüren. Das war zuvor nicht möglich. Im Jahre 2005 wurden die ersten ausführlichen quantitativen Studien veröffentlicht, in denen die zwei Genome Buchstabe um Buchstabe verglichen wurden. Es zeigte sich, dass von den 2,8 Milliarden DNA-Buchstaben – den Nukleotiden – der menschlichen DNA nur 2,4 Milliarden übereinstimmten mit denen des Schimpansen.2 Das ist also ein absoluter, genetischer Unterschied von 15 %. Außerdem fand das Konsortium im menschlichen Genom Dutzende von einzigartigen Protein-codierenden Genen ohne Gegenstück im Schimpansen-Genom (The Chimpanzee Sequencing and Analysis Consortium). Eine weitere Überraschung dieser vergleichenden Genom-Studien war, dass mindestens 17 Gene, die im Schimpansen funktionell sind, im Menschen durch Mutationen inaktiviert wurden (The Chimpanzee Sequencing and Analysis Consortium). Das Genom des Schimpansen beherbergt beispielsweise ein Gen, das für das Protein Caspase 12 codiert. Im Caspase-Gen des Menschen gibt es mehrere Mutationen, wodurch ein funktionelles Protein nicht synthetisiert werden kann. Die Genome besitzen offensichtlich Gene, die nicht gleichermaßen lebensnotwendig sind und leicht inaktiviert werden können. Das aktive Caspase-Protein startet normalerweise ein genetisches Apoptose-(Zelltod-)Programm, das Zellen mit einer gestörten Kalzium-Homeostase auflöst und auf diese Weise das Entstehen von Alzheimer verhindern kann. Das funktionelle Caspase-Protein, das bei Schimpansen angetroffen wird, erklärt somit, weshalb Alzheimer nicht bei diesen Affen vorkommt. Anscheinend beeinträchtigt die Inaktivierung des Caspase-Gens nicht den Erfolg, mit dem der Mensch sich fortpflanzt. Der redundante Charakter von Caspase 12 erklärt, warum das Gen defekt werden konnte. Die vergleichende Genom-Analyse aus dem Jahr 2005 zeigte außerdem defekte und inaktive Gene im Genom des Schimpansen. Diese Tatsache lässt im Rahmen evolutionstheoretischer Modellierungen auf eine erstaunliche Eigenschaft der mutmaßlichen Vorfahren beider Lebewesen schließen: Sie müssten genetisch viel reichhaltiger gewesen sein als die heutigen getrennten Arten. Anders gesagt: Der moderne Mensch und der heutige Schimpanse wären genetisch verarmte Organismen, wenn sie von einem gemeinsamen Vorfahren abstammen würden.
2006 erschien eine erweiterte Studie, in der alle Protein-codierenden Gene verglichen wurden, die man in beiden Organismen vorfindet, sogenannte Homologe. Danach weist das Genom des Menschen mehr als 689 Gene auf, die beim Schimpansen nicht vorkommen, während Schimpansen 86 Gene besitzen, die den Menschen fehlen (Demuth 2006). Das sind viele, wenn man in Betracht zieht, dass das Genom des Menschen insgesamt etwa 21.000 Protein-codierende Gene umfasst. Zudem gibt es große Unterschiede bezüglich der absoluten Zahl der Gene, da von den gleichen Genen mehr oder weniger im Genom vorkommen können, die man als copy-number-variations (CNV)* bezeichnet. Werden die homologen Gene eins zu eins abgeglichen, findet man einen Unterschied von 6,4 % (Cohen 2007). Es ist derzeit nicht bekannt, was diese CNV bedeuten. Obwohl sie zur genetischen Variabilität beitragen, vermutet man derzeit, dass sie bezüglich der phänotypischen Unterschiede zwischen Mensch und Schimpanse keine besondere Rolle spielen.
Im Jahr 2010 wurden die Y-Chromosomen von Mensch und Schimpanse neu sequenziert und genauer verglichen. Die genetischen und strukturellen Unterschiede der menschlichen MSY-Sequenz (d. h. die männliche spezifische Region) waren enorm. Verteilt über die gesamte menschliche MSY-Region gibt es 27 verschiedene Genfamilien (78 Gene), während Schimpansen nur 18 verschiedene haben (37 Gene). Im Y-Chromosom gibt es also de novo-Information, Gene, die nur im Menschen vorhanden sind und die eine Rolle bei der Entwicklung der Hoden zu spielen scheinen (Hughes et al. 2010). Die Autoren fassten ihre Ergebnisse wie folgt zusammen: „Der Unterschied im MSY-Gengehalt beim Schimpansen und beim Menschen ist eher vergleichbar mit dem Unterschied im autosomalen Gengehalt beim Huhn und beim Menschen, nach 310 Millionen Jahren Trennung.“
Die neuesten Analysen ermittelten 634 einzigartige de novo-Gene beim Menschen und 780 beim Schimpansen (Ruiz-Orera 2015). Möglicherweise kann diesen sogenannten Orphan-Genen* mehr Aussagekraft zugeschrieben werden, da sie den wirklichen Unterschied auf Protein-Ebene darstellen. Diese Gene (überwiegend lncRNA* und kleine Protein-Gene) werden vorwiegend im Gehirn exprimiert und gelten als neue und einzigartige genetische Informationen unbekannter Herkunft. Obwohl sich die potenzielle Funktion einiger dieser Gene aus ihrer Sequenz ableiten lässt, bleiben die Funktionen der meisten von ihnen unklar. Dies ist nicht zuletzt deshalb der Fall, weil sie nicht an Modell-Labortieren untersucht werden können, weil die Modellorganismen solche Gene nicht besitzen. Dennoch sind diese einzigartigen und artspezifischen Gene die Kandidatengene, um artspezifische Eigenschaften und Merkmale zu definieren. Und hier, im Bereich der Orphan-Gene, begegnen wir einer großen Überraschung der aktuellen Biologie: den Mikro-RNA-Genen*.
|
BLASTN-Algorithmus mit Gap-Extension: Sequenzierungssoftware. In der Bioinformatik ist BLAST (Basic Local Alignment Search Tool) ein Algorithmus zum Vergleich von primären biologischen Sequenzinformationen, wie beispielsweise den Aminosäuresequenzen von Proteinen oder den Nukleotiden von DNA- und/oder RNA-Sequenzen. Der Gapped BLAST-Algorithmus ermöglicht es, Lücken (Indels) in die zurückgegebenen Ausrichtungen einzubringen. Das Zulassen von Lücken bedeutet, dass ähnliche Regionen nicht in mehrere Segmente zerlegt werden, und neigt dazu, biologische Zusammenhänge stärker zu reflektieren. Bei der Gap-Extension-Methode werden Indels als Differenzen ausgewiesen. bp: Abkürzung für Basenpaar der DNA. Copy-number-variation (CNV): Das Phänomen, bei dem Abschnitte des Genoms wiederholt werden und die Anzahl der Wiederholungen im Genom zwischen den Individuen (hier: zwischen Menschen und Schimpansen) variiert. Denisovaner: Ausgestorbene Frühmenschen aus Asien. Enhancer: ein Stück DNA (50–1500 Basen), das dazu dient, Aktivatorproteine zu binden, um die Transkription eines bestimmten Gens zu erhöhen. exprimieren: Das Ablesen und Nutzen von Genen. Genom: das komplette Erbgut (DNA) eines Organismus. HAR (human accelerated region): DNA-Sequenzen, die viele Änderungen (Mutationen) aufweisen im Vergleich mit den entsprechenden Genen des Schimpansen. Genexpression: → exprimieren. Indel (Plural: Indels): Sammelbegriff für Insertion (Einfügung) oder Deletion (Verlust) von Basen in der DNA. In frame Mutation: eine genetische Mutation, die durch Einfügen einer Anzahl von Nukleotiden in eine DNA-Sequenz verursacht wird, die durch drei teilbar ist. Das wird den Proteincode nicht stören. lncRNA (long non-coding RNA): größeres, nicht-codierendes RNA-Molekül (>200 Nukleotide lang), das in Pflanzen und Tieren vorkommt. Diese RNA-Moleküle werden nicht in Proteine übersetzt und haben mehrere biologische Funktionen durch direkte Interaktionen mit DNA und/oder RNA. MikroRNA (abgekürzt miRNA): ein kleines, nicht-codierendes RNA-Molekül (etwa 22 Nukleotide lang), das in Pflanzen, Tieren und einigen Viren vorkommt. Es fungiert als post-transkriptioneller Regulator der Genexpression. Orphan-Gene: Gene, die nur in einer bestimmten Art vorkommen. Out of frame Mutation: Eine genetische Mutation, die durch Einfügen einer Anzahl von Nukleotiden in eine DNA-Sequenz verursacht wird, die nicht durch drei teilbar ist. Das wird den Proteincode zerstören. Promotor: Ein spezifisches Stück der DNA, das direkt dem Gen vorgelagert ist, welches die Transkription eines Gens initiiert. Protein-codierende DNA-Sequenzen: Solche Sequenzen der DNA (bzw. Gene), die in Proteine übersetzt werden. Viele andere Sequenzen erfüllen verschiedenste regulatorische Aufgaben („nicht-codierende DNA“).
|
|
|
Neue Informationen kennzeichnen die Arten
Mit der überraschenden Entdeckung von Tausenden neuen Mikro-RNA-Genen erhielten die Forscher im Jahr 2007 schon einen kleinen Vorgeschmack der biologischen Revolution, die ihnen in diesem Bereich bevorstand. Diese Gene codieren für kurze RNA-Moleküle, die die Expression von Hunderten anderen Genen regulieren können. Diese erst kürzlich im Genom entdeckten RNA-Gene erweisen den qualitativen Unterschied zwischen Menschen und Schimpansen als noch größer als zuvor bekannt. Mit Hilfe der modernsten Techniken wurden sowohl beim Schimpansen als auch beim Menschen sogar völlig neue einzigartige RNA-Gen-Familien entdeckt. Die Gruppe um den holländischen Genom-Forscher Ronald Plasterk beschrieb im Jahr 2006 447 neue, unbekannte Mikro-RNA-Gene, die nur im Gehirn von Primaten angetroffen wurden. Von diesen Genen waren 36 einmalig für den Menschen und 25 wurden nur im Schimpansen aufgefunden (Berezikov et al. 2006, Ponting & Lunter 2006). Seither hat sich die Anzahl der miRNAs beim Menschen vervielfacht (2555 wurden 2013 gemeldet).3 Voraussichtlich wird etwa ein Drittel von ihnen schließlich als echte miRNA validiert, wodurch sich die Informationslücke zwischen Mensch und Schimpanse weiter vergrößern wird.4 Schon diese Daten belegen, dass einmalige, einzigartige mikro-RNA-Gene die Genome von Mensch und Tier charakterisieren.
|
|
| Tab. 1: Zusammenfassung der in diesem Artikel erwähnten Arbeiten zum Vergleich der Genome von Mensch und Schimpanse. Soweit möglich wurden Zahlen anhand der in den Artikeln veröffentlichten Sequenzdaten ergänzt, um die wirklichen Ähnlichkeiten zu rekonstruieren. Nur wenn die Arbeiten alle Datensätze enthalten, ist eine genaue Überprüfung der Publikationen möglich. bp = Basenpaare. * Die Methode erlaubt keine Schätzung. **Nur 2,4 Milliarden bp der Sequenzen des Schimpansen-Genoms wurden im 2,8-Milliarden-bp-Humangenom gefunden. |
Darüber hinaus wurde noch eine Familie von Sequenzen angetroffen, die, bekannt als HARs*, das Genom des Menschen kennzeichnen. Die Abkürzung HAR steht für human accelerated regions. Es sind überwiegend RNA-Gene, die viele Änderungen (Mutationen) aufweisen im Vergleich mit den entsprechenden Genen des Schimpansen. Im menschlichen Genom gibt es mehr als 2700 solcher HARs. Oft haben sie sehr spezifische Merkmale. Das HAR1F-Gen wird z. B. nur in einem besonderen Typ Gehirn-Zellen, den Cajal-Retzius-Zellen, vorgefunden. Dort bestimmt das Gen, wie die sechs Schichten der Gehirnrinde während der embryonalen Entwicklung gefaltet werden müssen. Interessanterweise kommt das HAR1F-Gen nur bei den Primaten vor und ist nahezu monomorph. Das heißt, dass Schimpansen, Gorillas und Orang-Utans alle dieselbe Gen-Sequenz besitzen. Das HAR1F-Gen des Menschen aber unterscheidet sich auf 18 Positionen im Vergleich mit dem des Schimpansen. Außerdem sind diese Positionen mit den Unterschieden nicht zufällig betroffen. In der funktionellen RNA – für die dieses Gen codiert – bilden sie nämlich eine interne Schleife („loop“), welche durch eine Positionsbestimmung von jeweils zwei Nukleotiden, die wie ein winziger Reißverschluss wirken, stabilisiert wird (Terborg & Truman 2007). Diese Positionsbestimmung kann nicht graduell entstanden sein. Der Reißverschluss kann nur mittels einer paarweisen Positionierung gestaltet sein. Falls die Nukleotide nicht paarweise vorkommen, kann die Schlinge nicht stabilisiert werden. Eine instabile Schlinge würde vermutlich keinen reproduktiven Vorteil einbringen. Die HAR1F-Gene des Menschen besitzen quasi eine nichtreduzierbare Komplexität. Sollte das HAR1F-Gen schrittweise entstanden sein, so würde man nachweisen müssen, dass jede einzelne Mutation einen Vorteil ergibt und somit selektiert werden kann. Im Falle der HAR1F erscheint das als ein eher unwahrscheinlicher Vorgang.
Darüber hinaus zeigten Promotor*-Studien bei modernen Menschen und Schimpansen große Unterschiede. Es wurde festgestellt, dass nur 6.050 der 9.329 Promotor-Sequenzen ähnlich sind, während die Ähnlichkeit der übrigen Promotoren (35 %) weniger als 90 % betrug. Detaillierte Studien des Chromosoms 21 zeigten, dass die Promotoren der Schimpansengene oft sehr unterschiedlich reguliert waren im Vergleich zu den menschlichen Pendants (Deyneko 2010). Zusätzliche Studien erweisen auch große Unterschiede zwischen der Promotor-Aktivität bei Mensch und Schimpanse, da bis zu 10 % der Gene, die im Gehirn exprimiert* werden, bei den beiden Arten unterschiedlich exprimiert werden (Heissig 2005). Dies ist von Bedeutung, da es die Gehirnaktivität und die höheren kognitiven Funktionen beeinflusst.
|
|
|
|
16 % statt 1 %
Der genetische Unterschied zwischen Mensch und Schimpanse ist nicht nur quantitativ, sondern es gibt einen echten qualitativen Unterschied in Form neuer genetischer Information. Dies wurde 2018 umso deutlicher, als der Genomforscher Jeffrey P. Tomkins nochmals über 540 Millionen Basenpaare hochwertiger (zuverlässig sequenzierter) Schimpansen-DNA mit dem menschlichen Genom unter Verwendung des BLASTN-Algorithmus mit Gap-Extension* verglich. Er beobachtete eine Nukleotid-Identität von nur 84 %, also eine Differenz von 16 % (Tomkins 2018). Die heutige Biologie konfrontiert uns mit völlig neuer, artenspezifischer biologischer Information und mit einer unerwarteten Meta-Informationsebene wie der RNA-Gene, die die Expression anderer biologischer Information regulieren. Mehrere hundert Protein-codierende Gene, lncRNA- und Mikro-RNA-Gene tragen dazu bei, dass die Genome von Mensch und Schimpanse viel verschiedener sind als bisher angenommen.
Die Unterschiede sind am gravierendsten auf der Ebene der Genregulation, da ein Drittel der Promotor-Regionen der homologen Gene sehr unterschiedlich sind. Das bedeutet, dass nicht die „Werkzeuge“, die Protein-codierenden Gene an sich, die phänotypischen Unterschiede zwischen den beiden Kreaturen bestimmen, sondern vielmehr die Art und Weise, wie diese Werkzeuge exprimiert werden. Darüber hinaus bilden eine große Menge von miRNA-Genen sowie die HAR-Sequenzen die genetischen Grundlagen der mentalen und kognitiven Unterschiede.
|
| Der 1 – 2 %-Genom-Unterschied zwischen Mensch und Schimpanse entspricht einem veralteten Wissensstand. |
|
|
Die sequenzierten Genome der archaischen Menschen, Neandertaler und Denisovaner, sind dem modernen Menschen viel ähnlicher und unterscheiden sich stark vom Schimpansen. Die gemeinsame Abstammung des archaischen und modernen Menschen ist in der Regel leicht nachzuvollziehen, lässt aber die Schimpansen als Außengruppe zurück (O’Micks 2018). Die Daten des 21. Jahrhunderts zeigen, dass die genetische Kluft zwischen Mensch und Schimpanse sehr viel größer ist, als bisher angenommen und von den Medien popularisiert wurde. Wenn in den Medien noch immer propagiert wird, dass es einen nur 1–2 %igen genetischen Unterschied zwischen Menschen und Schimpansen gibt, ist das ein veralteter Wissensstand, mit dem man zu Unrecht suggeriert, dass der Mensch nur ein höherentwickelter Affe sei.
|
Anmerkungen
1 Man könnte sie als menschenspezifische Deletionen (Verluste) bezeichnen, aber diese Bezeichnung basiert auf der Annahme einer gemeinsamen Abstammung aller Primaten. Der Begriff „Deletion“ impliziert, dass die Sequenzen in der menschlichen Linie existierten und im Laufe der Zeit verloren gingen, was jedoch bereits eine evolutionstheoretische Interpretation ist.
2 Mittlerweile weiß man, dass es etwas mehr als 3 Milliarden Bausteine sind.
3 http://mirnablog.com/how-many-unique-mature-human-mirnas-are-there/
4 In einer persönlichen Mitteilung gab David Fromm, ein Experte für menschliche miRNAs, bekannt, dass der funktionell validierte Satz von humanspezifischen miRNAs-Genen derzeit etwa 130 miRNA-Genfamilien umfasst. Die validierende Arbeit geht sehr langsam voran, da die funktionellen Studien sehr zeitaufwändig sind.
|
|
|
Literatur
- Berezikov E et al. (2006)
- Diversity of microRNAs in human and chimpanzee brain. Nature Genetics 38,1375–1377.
- Britten RJ (2002)
- Divergence between samples of chimpanzee and human DNA sequences is 5 %, counting indels. Proc. Natl. Acad. Sci. 99, 13633–13635.
- Coghlan A (2002)
- Human-chimp DNA trebbled. New Scientist 2002, September 23.
- Cohen J (2007)
- Relative differences: The myth of 1 %. Science 316, 1836.
- Cserhati MF, Mooter ME, Peterson L, Wicks B, Xiao P, Pauley M & Guda C (2018)
- Motifome comparison between modern human, Neanderthal and Denisovan. BMC Genomics. 19, 472.
- Culotta E (2005)
- Chimp genome catalogs differences with humans. Science 309, 1468–1469.
- Demuth JP, De Bie T, Stajich JE, Cristianini N & Hahn MW (2006)
- The evolution of Mammalian gene families. PLoS ONE 2006. 1(1): e85.
- Deyneko IV, Kalybaeva YM, Kel AE & Blöcker H (2010)
- Human-chimpanzee promoter comparisons: property-conserved evolution? Genomics 96, 129–133.
- Gunter C & Dhand R (2005)
- The chimp genome. Nature 437, 47.
- Heissig F, Krause J, Bryk J, Khaitovich P, Enard W & Pääbo S (2005)
- Functional analysis of human and chimpanzee promoters. Genome Biol. 6, R57.
- Hughes JF et al. (2010)
- Chimpanzee and human Y chromosomes are remarkably divergent in structure and gene content. Nature 463, 536–539.
- International Human Genome Sequencing Consortium.
- Finishing the euchromatic sequence of the human genome. Nature 431, 931–945.
- King MC &Wilson AC (1975)
- Evolution at two levels in humans and chimpanzees. Science 188, 107–116.
- McLean CY, Reno PL et al. (2011)
- Human-specific loss of regulatory DNA and the evolution of human-specific traits. Nature 471, 216–219.
- O’Micks J (2018)
- Baraminic analysis of archaic and modern human genomes. J. Creation 32, 82–87.
- Pääbo S (2003)
- The mosaic that is our genome. Nature 421, 409–412.
- Page SL & Goodman M (2001)
- Catarrhine phylogeny: noncoding DNA evidence for a diphyletic origin of the mangabeys and for a human-chimpanzee clade. Mol. Phylogenet. Evol. 18, 14–25.
- Ponting CP & Lunter G (2006)
- Evolutionary biology: human brain gene wins genome race. Nature 442, 149–150.
- Prüfer K et al. (2012)
- The bonobo genome compared with the chimpanzee and human genomes. Nature 486, 527–531.
- Ruiz-Orera J, Hernandez-Rodriguez J et al. (2015)
- Origins of de novo genes in human and chimpanzee. PLoS Genet 11(12): e1005721.
- Terborg P & Truman R (2007)
- The HAR1F gene: a Darwinian paradox. J. Creation 21, 55–57.
- The Chimpanzee Sequencing and Analysis Consortium.
- Initial sequence of the chimpanzee genome and comparison with the human genome. Nature 437, 69–87.
- Tomkins JP (2018)
- Comparison of 18,000 de novo assembled chimpanzee contigs to the human genome yields average BLASTN alignment identities of 84 %. Answers Res. J. 11, 205–209. www.answersingenesis.org/arj/v11/chimpanzee_contig.pdf
- Wildman DE et al. (2003)
- Implications of natural selection in shaping 99.4 % nonsynonymous DNA identity between humans and chimpanzees: enlarging genus Homo. Proc. Natl. Acad. Sci. 100, 7181–7188.
- Wong K (2014)
- The 1 percent difference. Genome comparisons reveal the DNA that distinguishes Homo sapiens from its kin. Sci. Am. 311, 100.
|
|
|  |